AI is not magic. The tools that generate essays or hyper-realistic videos from simple user prompts can only do so because they have been trained on massive data sets. That data, of course, needs to come from somewhere, and that somewhere is often the stuff on the internet that’s been made and written by people.
The internet happens to be quite a large source of data and information. As of last year, the web contained 149 zettabytes of data. That’s 149 million petabytes, or 1.49 trillion terabytes, or 149 trillion gigabytes, otherwise known as a lot. Such a collective of textual, image, visual, and audio-based data is irresistible to AI companies that need more data than ever to keep growing and improving their models.
So, AI bots scrape the worldwide web, hoovering up any and all data they can to better their neural networks. Some companies, seeing the business potential, inked deals to sell their data to AI companies, including companies like Reddit, the Associated Press, and Vox Media. AI companies don’t necessarily ask permission before scraping data across the internet, and, as such, many companies have taken the opposite approach, launching lawsuits against companies like OpenAI, Google, and Anthropic. (Disclosure: Lifehacker’s parent company, Ziff Davis, filed a lawsuit against OpenAI in April, alleging it infringed Ziff Davis copyrights in training and operating its AI systems.)
Those lawsuits probably aren’t slowing down the AI vacuum machines. In fact, the machines are in desperate need of more data: Last year, researchers found that AI models were running out of data necessary to continue with the current rate of growth. Some projections saw the runway giving out sometime in 2028, which, if true, gives only a few years left for AI companies to scrape the web for data. While they’ll look to other data sources, like official deals or synthetic data (data produced by AI), they need the internet more than ever.
If you have any presence on the internet whatsoever, there’s a good chance your data was sucked up by these AI bots. It’s scummy, but it’s also what powers the chatbots so many of us have started using over the past two and a half years.
The web isn’t giving up without a fight
But just because the situation is a bit dire for the internet at large, that doesn’t mean its giving up entirely. On the contrary, there is real opposition to this type of practice, especially when it goes after the little guy.
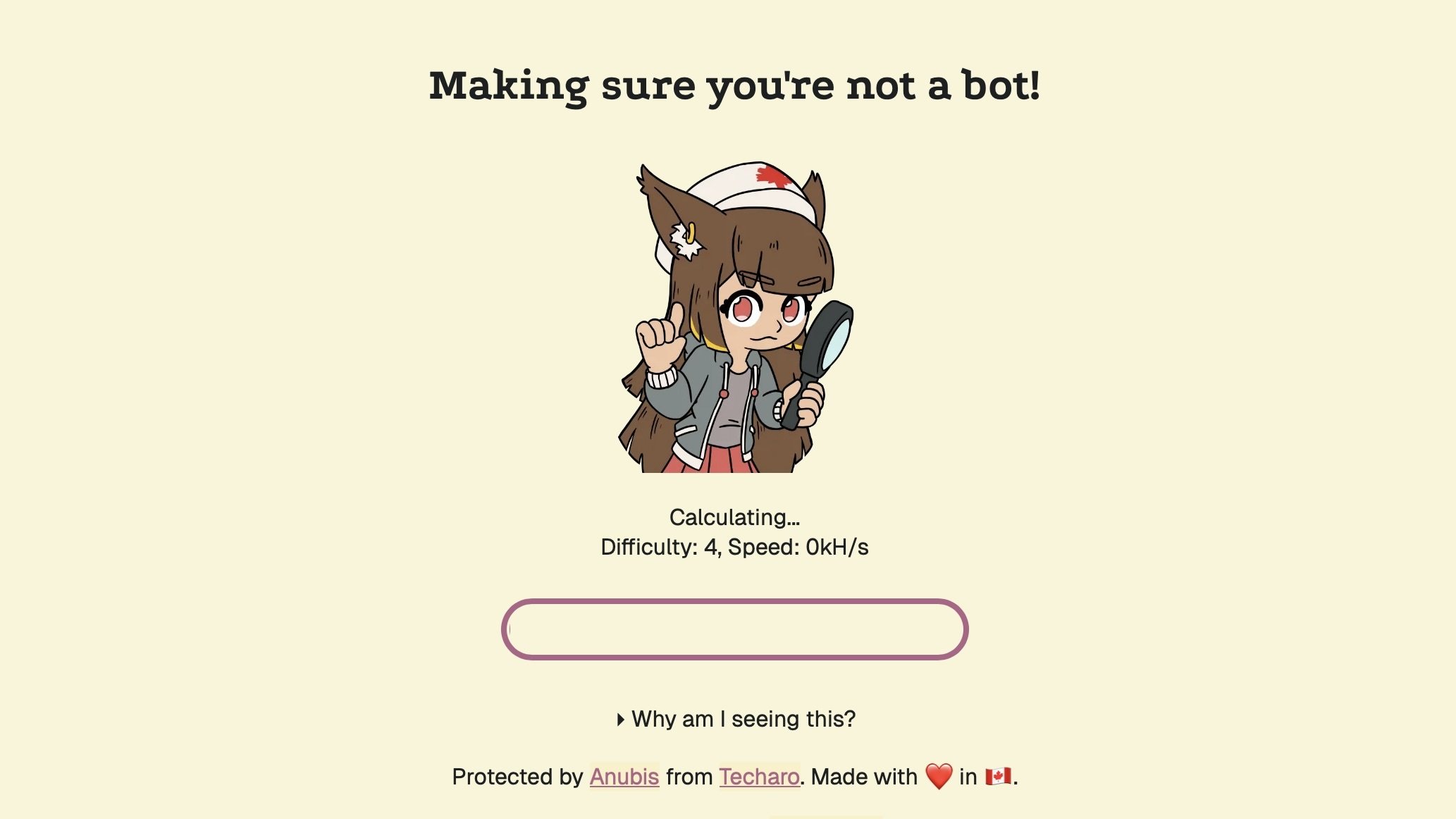
In true David-and-Goliath fashion, one web developer has taken it upon themselves to build a tool for web developers to block AI bots from scraping their sites for training data. The tool, Anubis, launched at the beginning of this year, and has been downloaded over 200,000 times.
Anubis is the creation of Xe Iaso, a developer based out of Ottawa, CA. As reported by 404 Media, Iaso started Anubis after she discovered an Amazon bot clicking on every link on her Git server. After deciding against taking down the Git server entirely, she experimented with a few different tactics before discovering a way to block these bots entirely: an “uncaptcha,” as Iaso calls it.
Here’s how it works: When running Anubis on your site, the program checks that a new visitor is actually a human by having the browser run cryptographic math with JavaScript. According to 404 Media, most browsers since 2022 can pass this test, as these browsers have tools built-in to run this type of JavaScript. Bots, on the other hand, usually need to be coded to run this cryptographic math, which would be too taxing to implement on all bot scrapes en masse. As such, Iaso has figured out a clever way to verify browsers via a test these browsers pass in their digital sleep, while blocking out bots whose developers can’t afford the processing power required to pass the test.
This isn’t something the general web surfer needs to think about. Instead, Anubis is made for the people who run websites and servers of their own. To that point, the tool is totally free and open source, and is in continued development. Iaso tells 404 Media that while she doesn’t have the resources to work on Anubis full time, she is planning to update the tool with new features. That includes a new test that doesn’t push the end-user’s CPU as much, as well as one that doesn’t rely on JavaScript, as some users disable JavaScript as a privacy measure.
If you’re interested in running Anubis on your own server, you can find detailed instructions for doing so on Iaso’s GitHub page. You can also test your own browser to make sure you aren’t a bot.
Iaso isn’t the only one on the web fighting back against AI crawlers. Cloudflare, for example, is blocking AI crawlers by default as of this month, and will also let customers charge AI companies that want to harvest the data on their sites. Perhaps as it becomes easier to stop AI companies from openly scraping the web, these companies will scale back their efforts—or, at the very least, offer site owners more in return for their data.
My hope is that I run into more websites that initially load with the Anubis splash screen. If I click a link, and am presented with the “Making sure you’re not a bot” message, I’ll know that site has successfully blocked these AI crawlers. For a while there, the AI machine felt unstoppable. Now, it feels like there’s something we can do to at least put it in check.